Monday, December 19, 2016
Feature engineering tips for improving predictions..
Visit my blog posted on wordpress https://asimovweb.wordpress.com/2016/12/19/feature-engineering-tips-for-improving-predictions/
Thursday, October 6, 2016
Choose your best platform for machine learning
My new blog entry on choosing best platform for machine learning based solution...
https://asimovweb.wordpress.com/2016/10/06/choose-your-best-platform-for-machine-learning-solution/
Moving to wordpress blog
I have moved my blog to wordpress , Please continue to follow me at https://asimovweb.wordpress.com/
Sunday, May 1, 2016
Fast forward transformation process in data science with Apache Spark
Data Curation :
R Language - Widely adopted in data science with lot of supporting libraries
Mat lab - Commercial tool with lot of builtin libraries for data science
Apache Spark - New, powerful and gaining traction, Spark on Hadoop provides distributed and Resilient architecture help to fasten the curation process by multiple times.
Recent Study
Effective Utilization of resources:
Optimized transformation:
Integration to Hadoop Eco System
Support for multiple languages:
Curation is a critical process in data science that helps to prepare data for feature extraction to run with machine learning algorithms. Curation generally involves extracting, organising, integrating data from different sources. Curation may be a difficult and time consuming process depending on the complexity and volume of the data involved.
Most of the time data won't be readily available for feature extraction process, data may be hidden is unobstructed and complex data sources and has to undergo multiple transformational process before feature extraction .
Also when the volume of data is huge this will be a huge time consuming process and can be a bottle neck for the whole machine learning pipeline.
General Tools used in Data Science :One of my project involved curing and extracting the features from huge volume of data in natural language conversation text. We started with using R programming language for the transformation process, R language is simple with lot of functionalities in statistics and data science space but has limitations in terms of computation and memory and in turn efficiency and speed. We tried to migrate the transformation process to Apache Spark and observed tremendous improvement in the performance of transformation, We were able to bring down the time for transformation from more day to almost an hour of time for huge volume of data.
Here are some of the benefits that I would like to highlight the benefits of Apache Spark over R.
By default R runs in a single core and is limited by the capabilities of the single core and memory usage. Even though you have multi core system R is limited with using only one core, for memory it has the process limitations of a 32 bit R execution with virtual memory user space of 3 GB and for 64 bit R execution limited to amount of RAM. R has some parallel lib packages that can help to span the processing to multi cores.
Spark can run in distributed form with the processing running on executors with each executor running on its own process utilizing the cpu and memory.Spark brings the concept of RDD (Resilient Distributed Dataset) to achieve distributed , resilient and scalable processing solution.
Spark has the concept of Transformation and Actions where the transformation perform lazy evaluation of job execution until an Action task is being called and intern brings optimization when multiple transformations are involved before an Action task which leads to transferring the results back to the driver program
Spark integrates well in the Hadoop ecosystem with yarn architecture and can easily bind to HDFS , multiple NOSQL database like HBase, Cassandra etc.
Spark API's has support on multiple programming languages like Scala, Java and Python
Sunday, January 3, 2016
Google Auto Awesome Video - Is it a machine learning solution ???
Wish you all a very happy and a wonderful new year 2016 !!!
Happy to start the year with a blog covering some aspects on machine learning and this post is actually an inspiration from the new year eve celebration.
In the new year eve celebration with friends and I captured some photo moments using google photos app. The next day morning when I woke up I got a notification in mobile , would you like to review and save the video made out of photos in the new year eve event with some nice background music added, in google terms they call as Auto Awesome videos in google photos app.
I am happy to see the video that has been made automatically and ready to share , there is also a manual mode where we can customize photos for the video. But my interest is on the automatic creation and started thinking how this design could have been ?
At first cut I was able to sense this could potentially be a machine learning implementation and with my limited data science knowledge I thought to do provide some guess work on how this could have been designed while running at a large scale for millions of tenants at the server end
Let us understand the requirement in detail , given a collection of images we have to perform the following
Now let us analyse the type of machine learning solutions that could have potentially been used for this design
Disclaimer : This is purely my own guess work of the design and google might have done in a different way :)
Monday, December 7, 2015
NOSQL with RDBMS fallback:
NOSQL adoption becoming prominent across different critical applications to reap the benefits of performance, fault tolerance, high availability for bigger volume database needs. While migrating to NOSQL one of the risk that architects feel is what if the application gets into some unseen issues and take more time to fix , as NOSQL adoption is not battle tested across different domain and sectors and how to design some fallback strategy.
Few factors that people may think while migrating to NOSQL
Architects would like to design some fallback option as RDBMS where application can switch to RDBMS on unrecoverable NOSQL issues. This raises few questions in mind on how to design the same.
I can think of design depicted below to address the same.

Few components involved in the design are Apache Kafka receiving the updates and Apache Storm process the data to update the same to RDBMS. Both of these system are designed to work for big data needs in a reliable and distributed form.
Apache Kafka is a high performance message queuing system. Application pose the messages (Insert / Update / Delete) to Kafka message queue. To improve the performance with parallel processing the queue can be partitioned by table / region / logical data design as per the NOSQL model.
Apache Storm is a real time processing engine that can consume message through Spout component, do some processing through bolts and update the data to RDBMS. Storm has topologies to process guaranteed data processing, transactional mode of commitments that makes it suitable to handle partial failures and during commitments.
Benefits:
Wednesday, December 2, 2015
Next Generation Enterprise Application Architecture
New generation applications are architectured not only with the goal of desiging the application functionally and performing stable but also focuses on different aspects that are becoming critical
Scalability – Elastic scalability for all the layers of the application including data tier
Fault Tolerance - Ability to handle failure smartly and avoid cascading failures from and to dependent systems
High Availability – Ability to have application highly available on all layers including database even on data center failures
Efficient utilization of Infrastructure - Ability to scale up and down on demand
Faster access to underlying data on high load and data volumes
Ability to handle different data formats efficiently
Few reasons that are tied to this evolution are the need and benefits towards cloud adoption ( could be either private or public cloud ) and the need to handle huge data volume with faster response on the data tiers
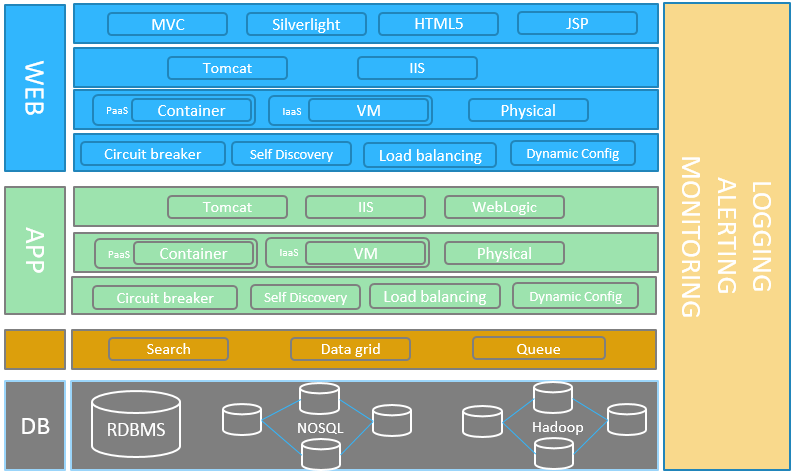
| Benefits | Solutions | |
|---|---|---|
| Physical -> IaaS -> PaaS | Elastic Scalability High Availability Efficient Infrastructure utilization Zero downtime deployment |
VMWare , Open Stack – Private Cloud IaaS AWS, Azure – Public Cloud IaaS , PaaS Cloud Foundry – PaaS on private and public cloud |
| Circuit Breaker | Fault Tolerance Better failure handling Avoid avalanche failures |
|
| Service Registry | Registry for dynamic instance scaling |
|
| Intelligent Load balancing | Intelligent Load Balancing utilizing the elastic scaling and self-discovery |
|
| Search | Quick search needs from huge data sets, full text search, pattern matching |
|
| Data Grid | Faster read write data, Reduce read / write overhead to database, high availability to data |
|
| Queue | Reliable data transfer across different data layers |
|
| NoSQL |
Big data – database needs Heavy Read / Write on high data volumes Faster response needs on the data High Availability on data Fault Tolerance on data Distributed database Scalable database |
|
| Hadoop |
Distributed file processing and storage ecosystem High speed batch (MapReduce) / real time ( Storm, Spark ) processing |
Different Hadoop distributions like Hortonworks, CloudEra,MapR |
Subscribe to:
Posts (Atom)