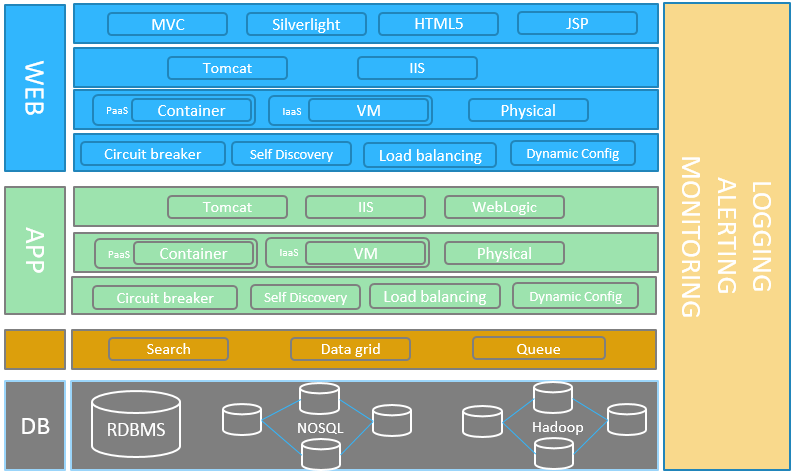
NOSQL adoption becoming prominent across different critical applications to reap the benefits of performance, fault tolerance, high availability for bigger volume database needs. While migrating to NOSQL one of the risk that architects feel is what if the application gets into some unseen issues and take more time to fix , as NOSQL adoption is not battle tested across different domain and sectors and how to design some fallback strategy.
Few factors that people may think while migrating to NOSQL
Architects would like to design some fallback option as RDBMS where application can switch to RDBMS on unrecoverable NOSQL issues. This raises few questions in mind on how to design the same.
I can think of design depicted below to address the same.

Few components involved in the design are Apache Kafka receiving the updates and Apache Storm process the data to update the same to RDBMS. Both of these system are designed to work for big data needs in a reliable and distributed form.
Apache Kafka is a high performance message queuing system. Application pose the messages (Insert / Update / Delete) to Kafka message queue. To improve the performance with parallel processing the queue can be partitioned by table / region / logical data design as per the NOSQL model.
Apache Storm is a real time processing engine that can consume message through Spout component, do some processing through bolts and update the data to RDBMS. Storm has topologies to process guaranteed data processing, transactional mode of commitments that makes it suitable to handle partial failures and during commitments.
Benefits: